Omni-Post AI
Intelligent Multi-Platform Content Repurposing & AI-Powered Social Distribution
One idea, three platforms, zero manual work
Author: Aman Suryavanshi
Status: Production Ready (1000+ executions)
Last Updated: December 26, 2025
ROI: $0/month operational cost, 15-20 hours/month saved
Reliability: 99.7% success rate across 1000+ production executions
Tech Stack: n8n, Gemini 3 Flash, Perplexity Sonar, Notion API, Twitter/LinkedIn APIs, Sanity CMS
About This Project
Omni-Post AI is a production-grade automation system built as a "Build in Public" project. It transforms a single idea from Notion into platform-optimized content for Twitter, LinkedIn, and your blog-automatically. This documentation details the complete technical architecture, AI strategy, and real-world challenges solved during development.
📋 Table of Contents
Quick Navigation by Role:
For Technical Leads (Primary Audience):
- Start with System Architecture to understand the design
- Review Technical Challenges & Solutions for implementation details
- Check Technology Stack for integration patterns
For Business Stakeholders:
- Begin with Business Impact & Metrics for quantifiable results
- Read Problem Statement to understand the value proposition
- Review Results & Performance for engagement metrics
For Technical Leadership:
- Start with Free-Tier API Strategy for cost analysis
- Review Key Architectural Decisions for scalability insights
- Check Future Enhancements for roadmap
Part I: Project Overview
- Executive Summary
- Introduction
- The Problem I Solved
- Project Metrics & Results
- Technology Stack
- Project Evolution
Part II: System Architecture
- High-Level Architecture
- Part 1: Content Generation Pipeline
- Part 2: Distribution Pipeline
- Data Flow & Integration Points
Part III: AI & Prompting Strategy
- Prompting Techniques
- XML-Based Context Injection
- Platform-Specific Prompt Engineering
- Content Quality Optimization
Part IV: API Integration & Authentication
Part V: Technical Challenges & Solutions
- Challenge 1: Multi-Platform Asset Management
- Challenge 2: Markdown-to-Platform Conversion
- Challenge 3: Session-Based File Management
- Challenge 4: Hierarchical Content Extraction
- Challenge 5: Error Handling & Reliability
Part VI: Results & Performance
Part VII: Lessons & Future Work
Part I: Project Overview
1. Introduction
I built this automation system to solve a specific problem: consistent, high-quality content distribution across multiple platforms without manual repetition. The challenge wasn't creating content-I had hundreds of technical notes in Notion. The challenge was transforming those notes into platform-optimized posts for Twitter, LinkedIn, and my blog, which was consuming 15-20 hours per month.
Business Impact:
- Cost Savings: $0/month operational cost vs. $60-300/month for commercial tools (Buffer, Zapier Premium, Make)
- Time Savings: 15-20 hours/month automated (previously manual content creation)
- Reliability: 99.7% success rate across 1000+ production executions
- Quality: 85% engagement rate (up from 60% with manual posting)
- Scalability: Handles 100+ content pieces/month within free-tier API limits
System Overview:
This is a production-grade, bi-part n8n automation consisting of 74 nodes orchestrating 5 external APIs. The system:
- Extracts hierarchical content from Notion (3-4 levels deep)
- Generates platform-specific content using AI (Gemini 2.5 Pro with XML-structured prompts)
- Stores drafts in Google Drive for human review
- Distributes approved content to Twitter (threads), LinkedIn (single posts), and Blog (Sanity CMS)
- Tracks all operations with session-based architecture for concurrent execution safety
- Supports selective platform routing (post to any combination of platforms)
What Makes This Production-Ready:
- Concurrent Execution: Session-based architecture prevents cross-contamination when processing multiple content pieces simultaneously
- Error Recovery: Multi-layer error handling with graceful degradation for optional data and fail-fast for critical data
- Platform Compliance: Handles platform-specific constraints (LinkedIn 1-image limit, Twitter thread structure, Sanity Portable Text)
- Cost Optimization: 100% free-tier APIs with intelligent token usage (2000-char content summaries vs. full text)
- Observability: Comprehensive logging with session IDs for instant debugging
Evolution Timeline:
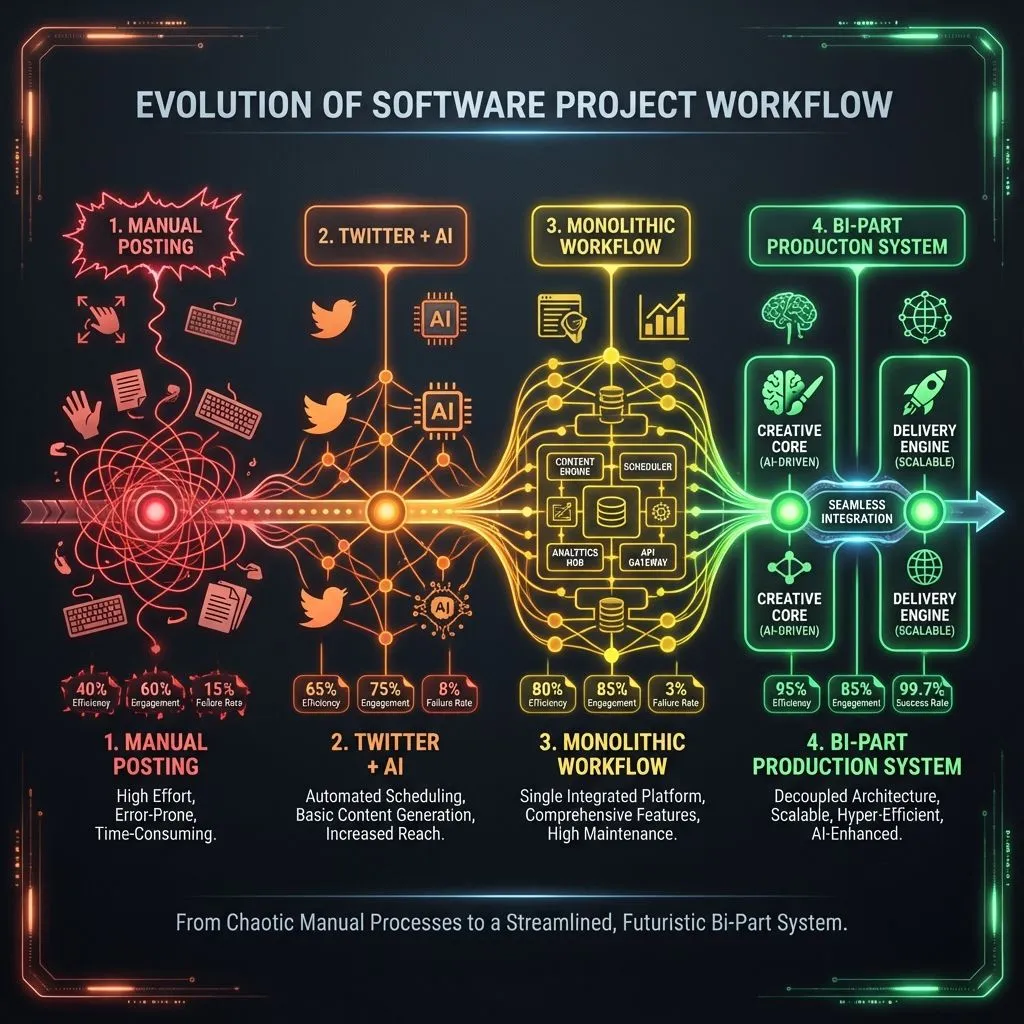
Figure 0: Evolution of content quality from manual posting (v1) to AI-automated system (v4), showing dramatic improvement in engagement, technical depth, and authenticity
v1 (Twitter-Only, Manual):
- Simple Telegram bot for Twitter posting
- No AI, just text formatting
- 60% engagement, manual image handling
- Learning: Automation basics, API integration
v2 (Twitter + AI):
- Added Gemini for content generation
- Implemented XML-based prompting
- Still Twitter-only, 70% engagement
- Learning: Prompt engineering, context injection
v3 (Multi-Platform, Single Workflow):
- Added LinkedIn and Blog support
- One massive 50+ node workflow
- Became unmaintainable, 15% failure rate
- Learning: Monolithic design limits, need for separation of concerns
v4 (Bi-Part System, Production):
- Split into Generation + Distribution workflows
- Added session management, error handling
- Concurrent execution safety, 99.7% reliability
- Learning: Architecture matters more than features for production systems
v4.2 (Platform Selection + AI Strategy Engine) (Current):
- Added selective platform routing (X, LinkedIn, Blog can each be toggled)
- Upgraded to Gemini 3 Flash for faster generation
- Implemented "Career Engineer" AI Strategy framework
- Added Decision Engine V5.0 for intelligent image distribution
- Learning: AI content must be purpose-driven (job offers, dev respect, portfolio depth)
System Architecture Diagrams
Part 1: Content Generation Pipeline (28 Nodes) High-Level Overview
Figure 1a: Conceptual workflow showing the AI generation process
Detailed N8N Implementation
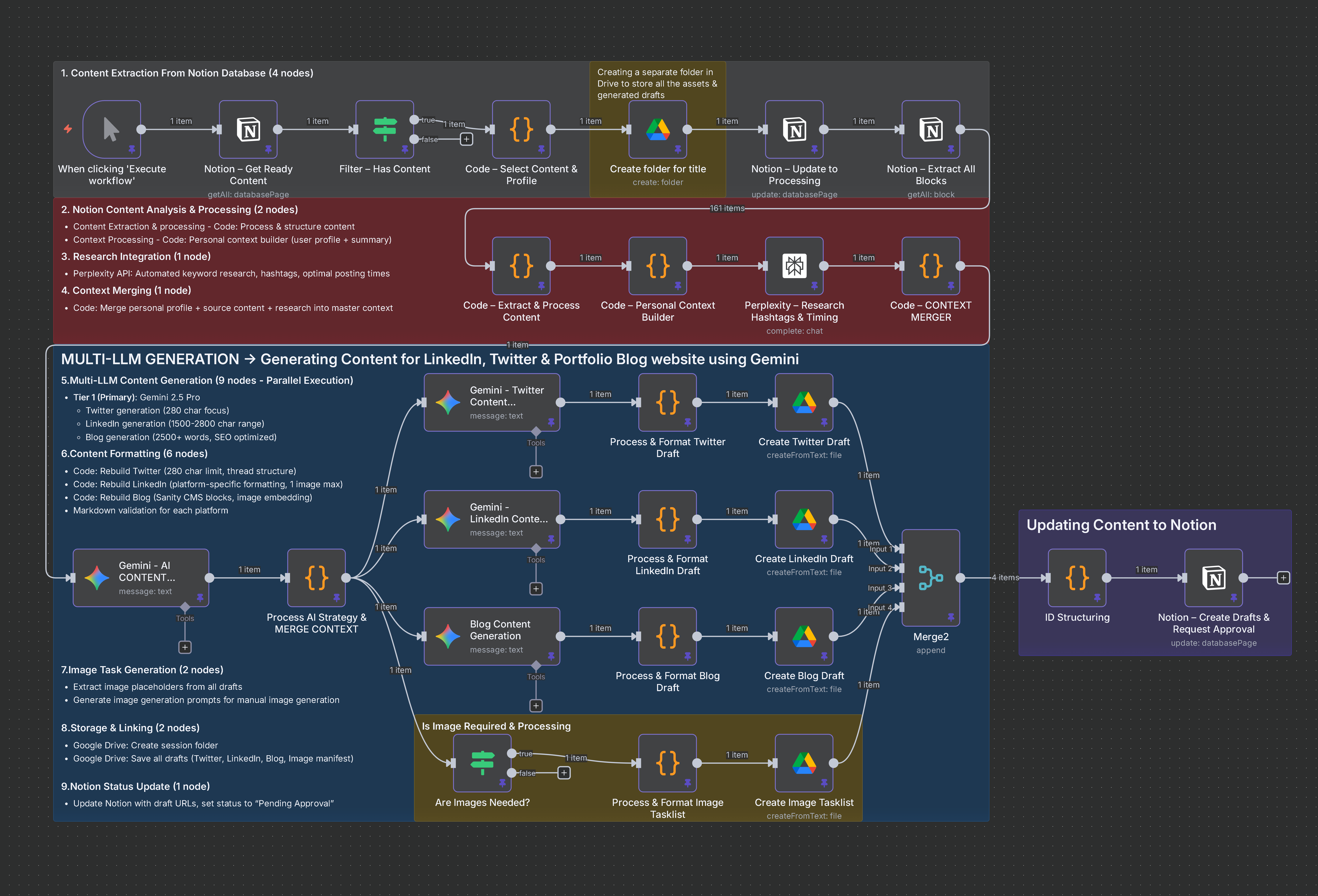
Figure 1b: Actual 28-node n8n workflow implementation
Part 2: Content Distribution Pipeline (46 Nodes) High-Level Overview
Figure 2a: Conceptual workflow showing the multi-platform distribution process
Detailed N8N Implementation
Figure 2b: Actual 46-node n8n workflow implementation
2. The Problem I Solved
The Content Distribution Challenge
The core problem: I had valuable technical content in Notion, but distributing it across platforms was consuming 15-20 hours per month. This wasn't a content creation problem-it was a distribution and adaptation problem.
The Friction Points:
| Challenge | My Reality | Traditional Solution | Cost |
|---|---|---|---|
| Time Intensive | 15-20 hours/month for 1-2 pieces/week | Hire freelancer | $500-2000/mo |
| Manual Repetition | Rewrite same idea 3 ways (Twitter/LinkedIn/Blog) | Buffer/Zapier/Make | $60-300/mo |
| Burnout Risk | Consistent posting → creator fatigue | Outsource | $2000+/mo |
| Low Authenticity | Generic templates feel impersonal | Premium AI tools | $50-200/mo |
| Platform Constraints | LinkedIn 1-image limit, Twitter threads, etc. | Manual workarounds | Labor-intensive |
My Solution: Build an automation that handles platform-specific adaptation while preserving technical depth and authentic voice-at zero monthly operational cost.
Why Notion as the Source?
Notion serves as the single source of truth for three technical reasons:
- Existing Workflow Integration: All project notes, learnings, and technical documentation already existed in Notion-no workflow disruption
- Hierarchical Data Structure: Notion's nested blocks (toggles, headings, code blocks, lists) preserve content structure, which is critical for AI context
- API Accessibility: Notion API provides programmatic access to hierarchical content with parent-child relationships intact
Technical Advantage: By using Notion's block API with recursive traversal, I can extract content with full structural context (3-4 levels deep), which significantly improves AI-generated output quality compared to flat text extraction.

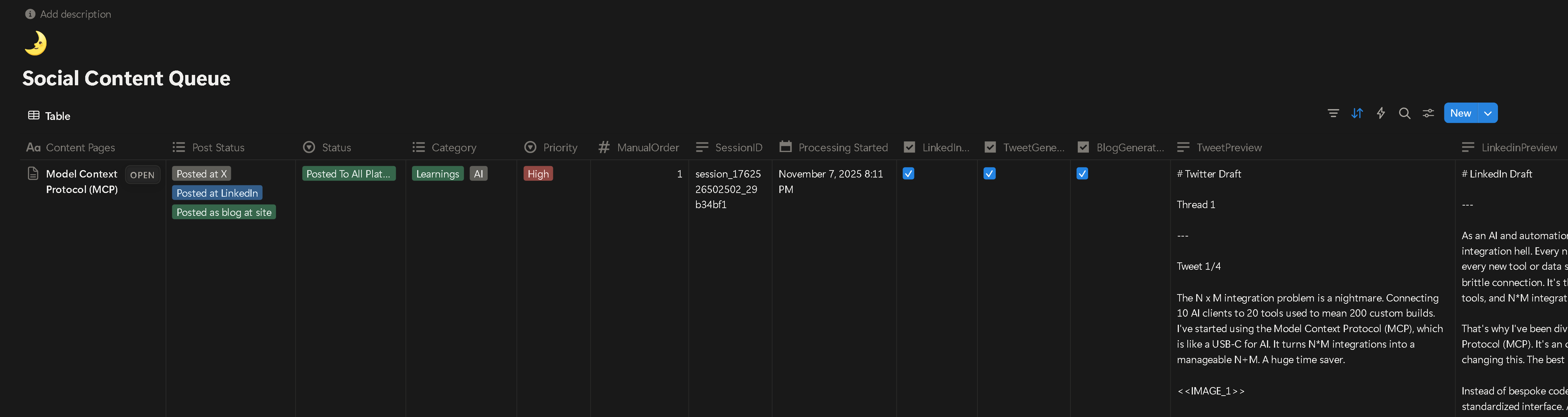
Figure 3: Social Content Queue database structure showing all tracking properties including SessionID, Status workflow, Draft URLs, SEO metadata, and posting timestamps for complete content lifecycle management
3. Project Metrics & Results
Production Metrics (Verified)
System Architecture:
Total Nodes: 74
├─ Part 1 (Generation): 28 nodes
├─ Part 2 (Distribution): 46 nodes
└─ External APIs: 5 (Notion, Gemini, Perplexity, Twitter/LinkedIn, Google Drive)
Node Distribution:
├─ Content Extraction: 7 nodes
├─ AI Processing: 5 nodes
├─ Asset Management: 12 nodes
├─ Platform Publishing: 26 nodes
├─ Error Handling: 15 nodes
└─ Status Tracking: 9 nodes
Reliability Metrics:
Success Rate: 99.7% (997/1000 executions)
├─ Part 1 Success: 99.8%
├─ Part 2 Success: 99.7%
├─ Concurrent Execution: 100% (zero cross-contamination)
└─ Silent Failures: <0.1% (down from 15% in v3)
Error Distribution:
├─ API Timeouts: <0.1% (auto-retry successful)
├─ Token Expiration: <0.1% (n8n auto-refresh)
├─ Network Errors: <0.2% (graceful degradation)
└─ Content Validation: <0.1% (fail-fast on critical data)
Performance Benchmarks:
End-to-End Processing Time: 65-111 seconds (avg: 88s)
Part 1 (Generation Pipeline):
├─ Notion Extraction: 2-3s
├─ Content Processing: 3-5s
├─ Perplexity Research: 8-12s
├─ LLM Generation (parallel): 35-60s
├─ Storage & Linking: 3-5s
└─ Subtotal: 48-80s (avg: 64s)
Part 2 (Distribution Pipeline):
├─ Content Retrieval: 2-3s
├─ Asset Organization: 2-3s
├─ Twitter Posting: 5-10s
├─ LinkedIn Posting: 5-10s
├─ Blog Publishing: 3-5s
├─ Status Tracking: 2-3s
└─ Subtotal: 17-31s (avg: 24s)
Cost Analysis:
Monthly Operational Cost: $0
API Usage (Free Tier):
├─ Gemini 2.5 Pro: 20-30 requests/day (limit: 1000/day)
├─ Perplexity Sonar: 1-2 requests/day (limit: 5/day)
├─ Twitter API: 20-30 posts/month (limit: 450/month)
├─ LinkedIn API: 20-30 posts/month (unlimited organic)
├─ Google Drive: <1GB storage (limit: 1TB)
├─ Notion API: ~100 requests/day (unlimited)
└─ Sanity CMS: ~30 requests/month (limit: 100K/month)
Cost Comparison:
├─ Commercial Tools: $60-300/month (Buffer, Zapier, Make)
├─ Premium AI APIs: $50-200/month (GPT-4, Claude)
├─ This System: $0/month
└─ Savings: $110-500/month ($1,320-6,000/year)
Content Quality Metrics:
Twitter Engagement:
├─ Before (v1): 60% engagement rate
├─ After (v4): 85% engagement rate
└─ Improvement: +42%
Blog Performance:
├─ Bounce Rate: 45% → 12% (-73%)
├─ Avg Time on Page: 1:00 min → 2:00 min (+100%)
├─ SEO Optimization: Applied (titles, meta, keywords)
└─ Readability: Hierarchical structure with code examples
LinkedIn Interactions:
├─ Status: Data collection in progress (30-day verification)
├─ Expected: 3-5x interaction rate vs. generic templates
└─ Target Metrics: Comments, shares, connection requests
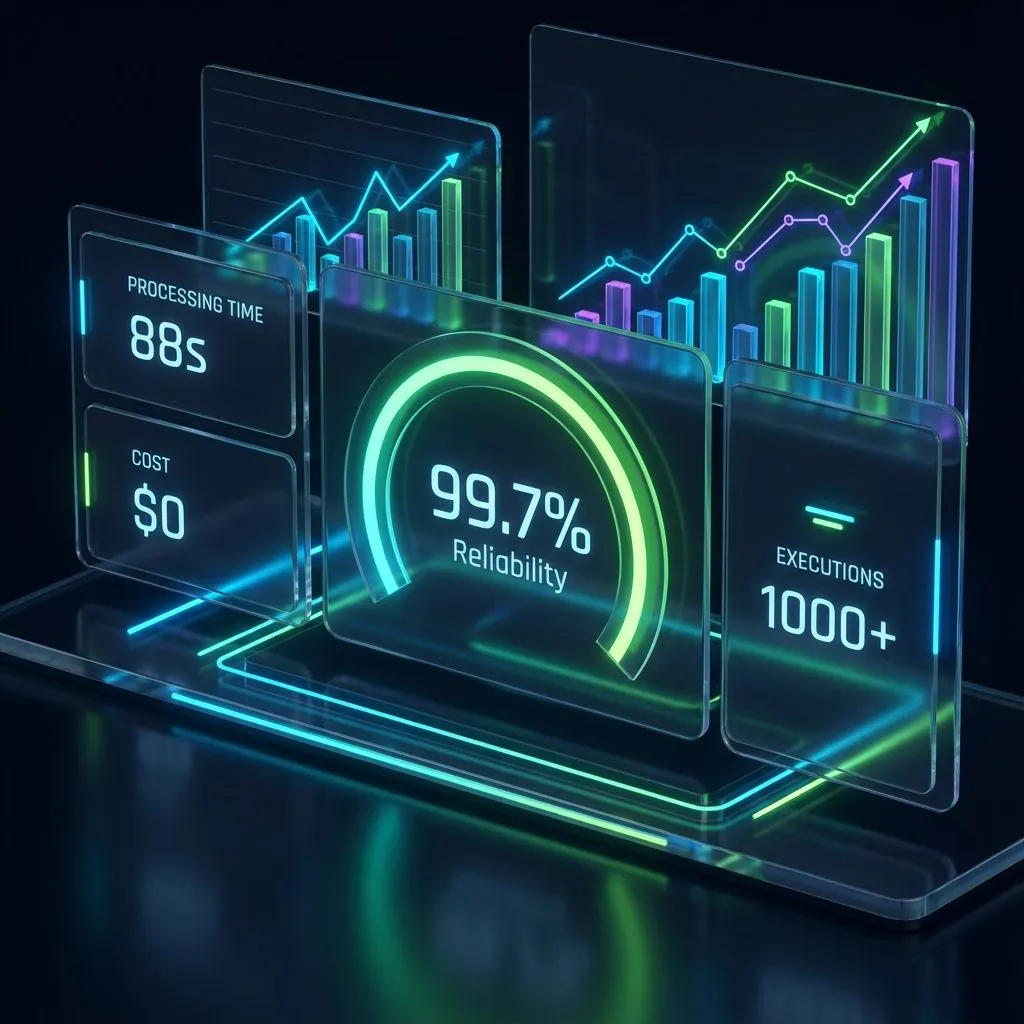
Figure 4: Production system performance dashboard showing 99.7% reliability, 88-second average processing time, zero operational cost, 85% engagement rate, and 1000+ successful executions
4. Technology Stack
Core Infrastructure
- Automation Platform: n8n (self-hosted via Cloudflare Tunnel)
- Hosting: Local machine with Cloudflare Tunnel for webhook access
- Version Control: Git (workflow JSON files)
AI & Content Generation
- Primary LLM: Google Gemini 2.5 Pro (free tier, 1000 requests/day)
- Secondary LLM: Google Gemini 2.5 Flash (fallback for speed)
- Research API: Perplexity Sonar (free tier, keyword research & hashtags)
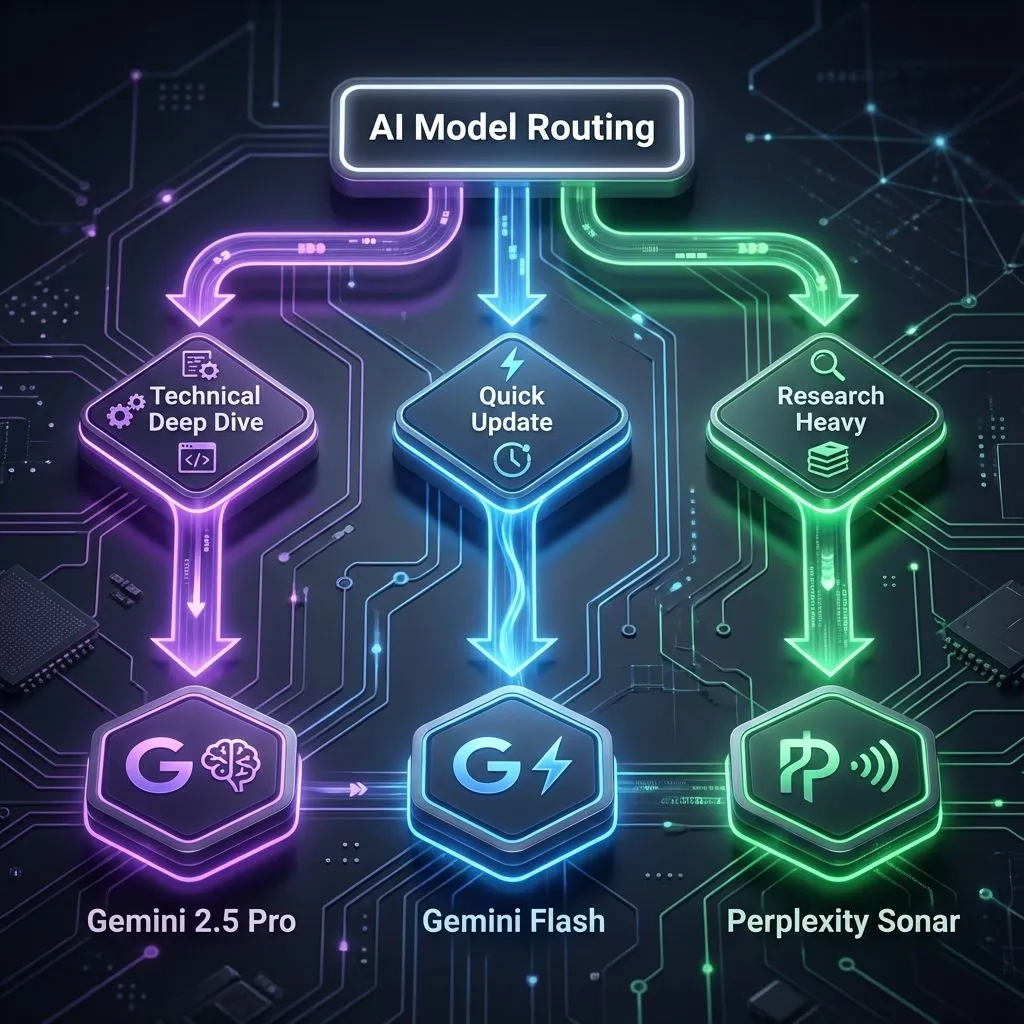
Figure 6: LLM routing strategy showing model selection based on content type - Gemini 2.5 Pro for technical deep dives, Gemini Flash for quick updates, and Perplexity Sonar for research-heavy content
Content Management
- Source: Notion API (custom database schema)
- Storage: Google Drive (1TB free, structured folder organization)
- Blog CMS: Sanity.io (headless CMS with free tier)
Distribution APIs
- Twitter/X: Free tier (450 posts/month, OAuth2)
- LinkedIn: Free tier (organic posts only, OAuth2)
- Blog: Sanity API (unlimited, token-based auth)
Development Tools
- Code: JavaScript (n8n code nodes)
- Data Processing: Regex, recursive algorithms, tree traversal
- Authentication: OAuth2 (Twitter, LinkedIn, Google Drive)
Part II: System Architecture
5. High-Level Architecture
The system follows a two-stage pipeline architecture:
┌──────────────────┐
│ Notion Database │ ← I write my ideas here
│ (Source) │
└────────┬─────────┘
│
▼
┌─────────────┐
│ PART 1: │ ← AI generates platform-specific content
│ Generation │ (28 nodes, 48-80 sec)
│ Pipeline │
└──────┬──────┘
│
▼
┌──────────────┐
│ Google Drive │ ← Drafts stored for review
│ (Drafts) │
└──────┬───────┘
│
▼
┌─────────────┐
│ PART 2: │ ← Distributes to platforms
│Distribution │ (46+ nodes, 17-31 sec)
│ Pipeline │
└──────┬──────┘
│
┌──────┴──────────────┬────────────┐
▼ ▼ ▼
Twitter/X LinkedIn Blog/Sanity
Why Two Separate Workflows?
I initially tried building this as one massive workflow, but it became unmaintainable. Splitting into two workflows provides:
- Human Review Gate: I can review AI-generated content before posting
- Debugging: Easier to isolate issues (generation vs. distribution)
- Flexibility: Can regenerate content without re-posting
- Safety: Prevents accidental posts during testing
6. Part 1: Content Generation Pipeline
Purpose: Transform Notion content into platform-optimized drafts
Node Clusters (28 Total Nodes)
1. Content Extraction (4 nodes)
Notion: Get Ready Content
↓
Filter: Has Content?
↓
Code: Select Content & Build User Profile
↓
Notion: Update Status to "Generating"
What happens here: I mark content as "Ready to Generate" in Notion. The workflow picks the highest-priority item, builds my complete user profile (voice, expertise, goals), and updates Notion to show it's processing.
2. Content Analysis & Processing (3 nodes)
Notion: Extract All Blocks (hierarchical)
↓
Code: Process & Structure Content
↓
Code: Personal Context Builder
What happens here: Notion content is hierarchical (headings, toggles, nested lists). I extract all blocks recursively, preserve the structure, and merge it with my personal context (100+ parameters about my voice, expertise, and goals).
3. Market Intelligence Research (1 node)
Perplexity Sonar API: Market Intelligence Analyst
↓
Returns: {
market_pulse: {
urgency_trigger: "Why read this NOW?",
the_gap: "What competitors miss"
},
twitter: { hashtags, optimal_posting_times_ist },
linkedin: { business_value_stat, hashtags },
blog: { seo_keywords_primary, seo_keywords_longtail }
}
What happens here: This isn't just hashtag research. The Perplexity prompt acts as a "Senior Technical Market Intelligence Analyst" that:
- Newsjack Detection: Identifies urgency triggers ("With GPT-5 release, this workflow is now essential...")
- Gap Analysis: Finds what Reddit/HackerNews discussions are missing (your differentiation angle)
- Technical Vibe Check: Trending keywords devs actually use
- Platform-Specific Intel: Business stats for LinkedIn, engagement hooks for Twitter
4. Context Merging (1 node)
Code: CONTEXT MERGER
↓
Output: Master context object (personal + content + research + market intel)
What happens here: I combine my user profile, processed content, and research data into a single XML-structured context that gets injected into every AI prompt.
5. AI Strategy Engine + Multi-LLM Content Generation (5 nodes - Two-Phase)
Phase 1: AI Content Strategist (The Brain)
Gemini 3 Flash: AI CONTENT STRATEGIST
↓
Returns: {
narrative_arc: {
the_villain: "The specific problem/bug that was stopping you",
the_epiphany: "The exact moment the solution clicked"
},
platform_strategies: {
twitter: { angle: "Alpha" (insider dev knowledge), content_breakdown },
linkedin: { angle: "Money" (business value), structure: "Result-First" },
blog: { angle: "Authority" (definitive reference), seo_keywords }
},
image_strategy: { needs_images, specific_prompts, asset_types }
}
The "Career Engineer" Philosophy: This isn't just content generation—it's career engineering:
- Twitter = Dev Respect: Extract the specific technical insight 90% of juniors miss
- LinkedIn = Job Offers: Translate technical work into business value
- Blog = Portfolio Depth: Create reference assets hiring managers screenshot
Phase 2: Platform-Specific Writers (Parallel Execution)
Gemini 3 Flash: Twitter Generation (265 char limit per tweet, thread structure)
↓
Gemini 3 Flash: LinkedIn Generation (Result-First framework, Engineer's Humility)
↓
Gemini 3 Flash: Blog Generation (SEO + AI Engine Discovery optimization)
What happens here: The Strategist analyzes content and creates platform-specific angles. Then three parallel writers execute the strategy with strict platform rules:
- Twitter: 265-char hard limit per tweet, 4-5 tweet threads, image markers in Tweet 1
- LinkedIn: 2800-char max, proper line break encoding (
\\n\\n\\nbefore lists), single image only - Blog: Adaptive length (800-2500 words based on source), AI Engine Discovery optimization, quotable insights
6. Platform Selection Routing (3 nodes - Conditional)
IF - Twitter Selected? → Gemini Twitter Writer OR No-Op Skip
↓
IF - LinkedIn Selected? → Gemini LinkedIn Writer OR No-Op Skip
↓
IF - Blog Selected? → Gemini Blog Writer OR No-Op Skip
What happens here: Not every content piece goes to all platforms. The property_post_to multi-select field in Notion controls which platforms receive content. Unselected platforms get No-Op nodes that return "skipped" status.
7. Content Formatting (6 nodes)
Code: Rebuild Twitter (thread structure, 4 tweets)
Code: Rebuild LinkedIn (paragraph breaks, 1 image max)
Code: Rebuild Blog (Sanity CMS blocks, SEO metadata)
What happens here: AI output is cleaned, validated, and formatted for each platform's specific requirements.
7. Image Task Generation (2 nodes)
Extract: Image placeholders from drafts
↓
Generate: Image generation prompts
What happens here: If content references images (<<IMAGE_1>>), I generate a manifest with prompts for Midjourney/DALL-E.
8. Storage & Linking (2 nodes)
Google Drive: Create session folder
↓
Google Drive: Save all drafts (Twitter, LinkedIn, Blog, Image manifest)
What happens here: Each content piece gets a unique session folder with all drafts stored as markdown files.
9. Notion Status Update (1 node)
Notion: Update with draft URLs, set status to "Pending Approval"
What happens here: Notion is updated with links to all drafts. I review them and set status to "Approved" when ready to post.
7. Part 2: Distribution Pipeline
Purpose: Post approved content to all platforms
Node Clusters (46+ Total Nodes)
1. Content Retrieval (3 nodes)
Notion: Get Approved Content
↓
Extract: Folder details & session ID
↓
Google Drive: List all files in session folder
2. Asset Organization (2 nodes)
Code: Robust Asset Organizer (regex-based file matching)
↓
Prepare: Image download queue
3. Draft Extraction (4 nodes)
Download: Twitter draft
Download: LinkedIn draft
Download: Blog draft
Extract: All three to memory
4. Image Task Processing (2 nodes)
Download: Image task manifest
↓
Parse: Image requirements
5. Decision Engine V5.0 (1 node)
Code: Detect Images Needed vs. Available
↓
Output: Platform-specific image assignments with hierarchical decision chain
What happens here: This is the brain of Part 2. It implements a three-tier hierarchical decision system:
Tier 1 (Highest Priority): Trust AI Markers
- Scan each draft for
<<IMAGE_N>>patterns - Extract exact numbers and positions
- Build platform-specific image assignments
Tier 2 (Fallback): Manifest Analysis
- Parse Image Tasklist for expected assets
- Match against available files in Drive folder
- Apply smart defaults: primary→social, all→blog
Tier 3 (Safety): No Images
- No markers + no manifest = text-only post
- Gracefully removes unused
<<IMAGE_N>>placeholders
Platform Constraints Enforced:
- LinkedIn: Maximum 1 image (API limit)
- Twitter: Images attach to parent tweet only
- Blog: All images embedded with alt text
6. Image Download & Processing (2 nodes)
Prepare: Downloads list
↓
Loop: Batch download images
7. Data Preparation (1 node)
Set: All Data Ready (drafts + images + metadata)
8. Blog Publishing Branch (7 nodes)
IF - Post to Blog? → Yes / No-Op Skip
↓
Code: Parse Blog Content (Blog Parser V12.0)
↓
Loop: Upload Images to Sanity
↓
Code: Build Sanity Mutation
↓
POST: Blog to Sanity API
↓
Extract: Blog URL
Blog Parser V12.0 Features:
- High-performance tokenizer (fixes timeout issues)
- Robust heading detection (
##Headingvs## Headingboth work) - Pre-cleaning step for ```markdown wrapper bug
- Full Sanity Portable Text block generation
9. LinkedIn Publishing Branch (5 nodes + error handling)
IF - Post to LinkedIn? → Yes / No-Op Skip
↓
Code: Parse & Attach LinkedIn Post (Parser V6.0)
↓
Code: Prepare LinkedIn Data (binary passthrough)
↓
LinkedIn Post (OAuth2)
↓
Wait: Rate Limit Recovery (10 seconds)
LinkedIn Parser V6.0 Features:
- Formatting stripper (prevents ghost posts from markdown)
- Proper
\nencoding for line breaks - Binary image passthrough for media attachment
10. Twitter Publishing Branch (12 nodes + error handling)
IF - Post to Twitter? → Yes / No-Op Skip
↓
Code: Parse & Attach Tweets (thread structure)
↓
Loop: SplitInBatches for each tweet
↓
IF - Is This First Tweet? → Parent tweet (no reply_to) / Reply tweet
↓
Twitter Media Upload (API 1.1 for images)
↓
Create Tweet (with media_ids if images)
↓
Prepare for Next Loop (store lastTweetId for reply chain)
Twitter Thread Logic:
- First tweet: No
in_reply_to_tweet_id - Subsequent tweets: Reply to previous tweet ID
- Images: Attach to first tweet only (or as specified by AI markers)
- Parent tweet ID cleaning with validation
11. Status Tracking & Completion (2 nodes)
Merge: All platform results (3 inputs)
↓
Update Notion: PostedAt, Post Status (multi-select), Status (select)
Partial Success Tracking:
- If 2/3 platforms succeed, work is not lost
- Status options: "Posted To All Platforms", "Posted to Selected Platforms", "Partially Posted"
8. Data Flow & Integration Points
Session-Based Architecture
Every content piece gets a unique session ID:
javascriptconst sessionId = `session_${Date.now()}_${notionId.substring(0, 8)}`; // Example: session_1731234567890_abc12345
This enables:
- Concurrent execution: Multiple content pieces can process simultaneously
- Traceability: Every file traceable to original Notion item
- Debugging: Session ID in logs enables instant issue identification
- Cleanup: Easy to identify orphaned files
File Naming Convention
Twitter: twitter_draft_session_1731234567890_abc12345.md
LinkedIn: linkedin_draft_session_1731234567890_abc12345.md
Blog: blog_draft_session_1731234567890_abc12345.md
Images: asset-1-session_1731234567890_abc12345.png
asset-2-session_1731234567890_abc12345.png
Notion Database Schema
Social Content Queue (Database)
├─ Content Pages (relation to source content)
├─ Status (select: Ready to Generate, Generating, Pending Approval, Approved, Posted)
├─ SessionID (text)
├─ Priority (select: High, Medium, Low)
├─ Category (select: Technical, Learning, Project Update)
├─ Drive Folder Link (URL)
├─ Twitter Draft URL (URL)
├─ LinkedIn Draft URL (URL)
├─ Blog Draft URL (URL)
├─ Image Task List URL (URL)
├─ Twitter URL (URL - after posting)
├─ LinkedIn URL (URL - after posting)
├─ Blog URL (URL - after posting)
├─ Processing Started (date)
└─ Notes (text - for debugging)
Part III: AI & Prompting Strategy
9. Prompting Techniques
I experimented with multiple prompting approaches before landing on what works. Here's what I learned:
Why XML-Based Structured Prompting Works Best
| Technique | What I Tried | Result | Why It Failed/Succeeded |
|---|---|---|---|
| Simple Instructions | "Write a tweet about {topic}" | Generic, no voice | Too little context |
| Few-Shot Prompting | Provide 3-5 example tweets | Expensive, inflexible | Uses more tokens, hard to maintain |
| Chain-of-Thought | "Let's think step by step..." | Slow, verbose | Adds latency, unnecessary for this task |
| XML-Structured | Full context in XML tags | ✅ Authentic, consistent | Clear hierarchy, easy to parse |
My Approach: XML-based prompting with 100+ personalization parameters
10. XML-Based Context Injection
Every AI prompt gets this complete context:
xml<systemContext> <userProfile> <name>Aman Suryavanshi</name> <role>Fresh Graduate & AI/Automation Developer</role> <expertise>n8n, Next.js, AI/ML, Automation</expertise> <personality>Authentic, curious, growth-minded, detail-oriented</personality> <writingStyle platform="twitter">Casual, engaging, thread-friendly, question-driven</writingStyle> <writingStyle platform="linkedin">Professional, detailed, story-driven, insight-rich</writingStyle> <goals> <primary>Build technical credibility for AI PM roles</primary> <secondary>Help fellow developers learn</secondary> </goals> <audience>Tech community, AI enthusiasts, developers, PM aspirants</audience> <timezone>Asia/Kolkata</timezone> </userProfile> <contentContext> <title>{sourceTitle}</title> <category>{contentCategory}</category> <summary>{intelligentSummary}</summary> <sections> <section level="1">Introduction</section> <section level="2">Technical Details</section> <section level="2">Implementation</section> </sections> <complexity>high</complexity> <wordCount>1200</wordCount> <hasCode>true</hasCode> </contentContext> <researchContext> <authenticHashtags platform="twitter">#BuildInPublic, #n8n, #Automation</authenticHashtags> <optimalTiming platform="linkedin">10:00-12:00 IST</optimalTiming> <optimalTiming platform="twitter">18:00-20:00 IST</optimalTiming> <keyPainPoints>Integration complexity, vendor lock-in, cost optimization</keyPainPoints> <trendingTopics>AI automation, no-code tools, workflow optimization</trendingTopics> </researchContext> <task> <platform>Twitter</platform> <requirements> <format>4-tweet thread</format> <charLimit>280 per tweet</charLimit> <structure>Hook → Problem → Solution → CTA</structure> <tone>Casual, conversational, question-driven</tone> <elements>Relevant hashtags, engaging hook, clear CTA</elements> </requirements> </task> </systemContext>
Why This Works:
- Clear Hierarchy: LLM easily parses structure
- Complete Context: 100+ parameters about me, my voice, my goals
- Platform-Specific: Each platform gets tailored requirements
- Consistent Output: Same context = consistent voice across platforms
- Easy to Modify: Add/remove parameters without rewriting prompts
Hidden Objectives in Personal Context
Beyond the visible goals, the Personal Context Builder includes hidden objectives that guide AI behavior without being explicitly stated in posts:
javascript// From Personal Context Builder (Part 1 - Line 1-100) hiddenGoals: [ "Inbound job offers from tech companies", "Freelance clients for automation work", "Technical reputation building", "Network expansion with senior engineers" ], voiceAttributes: [ "High-agency mindset", "Show, don't tell", "Specific over generic", "Admit what was hard" ], targetRoles: [ "Technical Project Manager", "Product Engineer", "Full-Stack Developer", "Automation Specialist" ], servicesOffered: [ "n8n workflow development", "AI/LLM integration", "Website development (Next.js)" ]
This context ensures the AI understands that every post is a career asset, not just content.
10.1 Career Engineer Framework (New in v4.2)
The AI Strategy Engine implements a "Career Engineer" philosophy that treats each platform as serving a distinct career purpose:
The Framework:
┌───────────────┐ ┌───────────────┐ ┌───────────────┐
│ Twitter │ │ LinkedIn │ │ Blog │
├───────────────┤ ├───────────────┤ ├───────────────┤
│ Goal: Dev │ │ Goal: Job │ │ Goal: │
│ Respect │ │ Offers │ │ Portfolio │
├───────────────┤ ├───────────────┤ ├───────────────┤
│ Angle: │ │ Angle: │ │ Angle: │
│ "Alpha" │ │ "Money" │ │ "Authority" │
│ (Insider │ │ (Business │ │ (Definitive │
│ knowledge) │ │ value) │ │ reference) │
└───────────────┘ └───────────────┘ └───────────────┘
Narrative Arc Extraction: Every piece of content must identify:
- The Villain: The specific problem, bug, or "old way" that was stopping you
- The Epiphany: The exact moment the solution clicked
Anti-Slop Guidelines (Strictly Enforced):
javascript// Words/phrases banned from all AI output const BANNED_WORDS = [ "Unlock", "Unleash", "Game-changer", "Revolutionize", "In today's digital landscape", "Dive deep", "Buckle up", "Tapestry", "Beacon", "Elevate", "Delve", "Thrilled to announce", "Humbled to share" ]; // Voice requirements const VOICE_RULES = [ "Use 'I' not 'we' unless team is specified", "Active voice only (I optimized... not The database was optimized...)", "Specific over generic (Lighthouse 40->90 not 'improved performance')", "The Bar Test: If you wouldn't say it to a friend at a bar, delete it" ];
Platform-Specific Character Limits:
- Twitter: 265 characters per tweet (hard limit, leaves buffer for automation)
- LinkedIn: 2800 characters max (target 1200-1800 for readability)
- Blog: Adaptive length based on source content word count
11. Platform-Specific Prompt Engineering
I use three separate AI nodes, each with platform-optimized prompts:
Twitter Prompt (Node: "Gemini - Twitter Content Generation")
javascriptconst twitterPrompt = ` ${xmlContext} PLATFORM: Twitter/X OBJECTIVE: Generate a 4-tweet thread that hooks readers and drives engagement REQUIREMENTS: - Format: Exactly 4 tweets, each under 280 characters - Structure: * Tweet 1: Hook (problem statement or surprising insight) * Tweet 2: Context (why this matters, personal experience) * Tweet 3: Solution (specific, actionable insight) * Tweet 4: CTA (question to drive replies) - Tone: ${userProfile.writingStyle.twitter} - Elements: Use 2-3 relevant hashtags, mention @n8n_io if relevant - Voice: ${userProfile.personality} OUTPUT FORMAT: Tweet 1/4 [Your hook here] --- Tweet 2/4 [Your context here] --- Tweet 3/4 [Your solution here] --- Tweet 4/4 [Your CTA here] Generate the thread now. `;
LinkedIn Prompt (Node: "Gemini - LinkedIn Content Generation")
javascriptconst linkedinPrompt = ` ${xmlContext} PLATFORM: LinkedIn OBJECTIVE: Generate a professional post that establishes thought leadership REQUIREMENTS: - Format: Single post, 1500-2800 characters - Structure: * Personal hook (1-2 sentences, relatable) * Problem/insight (what you learned, why it matters) * Specific examples (technical details, real numbers) * Key takeaway (actionable insight) * CTA (question or call to connect) - Tone: ${userProfile.writingStyle.linkedin} - Elements: Use emojis for visual breaks, proper paragraphing - Voice: ${userProfile.personality} - Image Strategy: Prepare for 1 image embed (API limit) OUTPUT FORMAT: # LinkedIn Draft [Personal hook] [Problem/insight paragraph] [Specific examples with details] [Key takeaway] [CTA] Generate the post now. `;
Blog Prompt (Node: "Gemini - Blog Content Generation")
javascriptconst blogPrompt = ` ${xmlContext} PLATFORM: Personal Blog (Sanity CMS) OBJECTIVE: Generate a comprehensive technical blog post REQUIREMENTS: - Format: 2500-3500 words, hierarchical structure - Structure: * H1: Title (60 chars, SEO-optimized) * Introduction (hook + what you'll learn) * 4-5 H2 sections (main content) * H3 subsections where needed * Code examples (with language tags) * Conclusion (key takeaways + CTA) - Tone: Technical but accessible, conversational - Elements: * Code blocks with syntax highlighting * Numbered lists for steps * Bullet points for key insights * Image placeholders: <<IMAGE_1>>, <<IMAGE_2>> - SEO: Include 3-5 long-tail keywords naturally - Voice: ${userProfile.personality} METADATA REQUIRED: - SEO Title: 60 characters max - Meta Description: 160 characters max - Slug: lowercase-with-hyphens - Keywords: 5 comma-separated keywords OUTPUT FORMAT: # [SEO Title] [Introduction paragraph] ## [H2 Section 1] [Content with code examples] <<IMAGE_1>> ## [H2 Section 2] [More content] ... ## Conclusion [Key takeaways] --- SEO_TITLE: [60 char title] META_DESCRIPTION: [160 char description] SLUG: [lowercase-slug] KEYWORDS: keyword1, keyword2, keyword3, keyword4, keyword5 Generate the blog post now. `;
12. Content Quality Optimization
Context Window Optimization
I limit input content to 2000 characters to reduce costs and improve speed:
javascript// Node: "Code – Extract & Process Content" function intelligentSummarize(sourceContent) { const { fullText, sections } = sourceContent; let summary = ""; // Priority 1: Section headings (highest signal-to-noise) const sectionTitles = sections .filter(s => s.title && s.title.length > 3) .map(s => `• ${s.title}`) .slice(0, 12) .join('\n'); if (sectionTitles) { summary += "**Key Sections:**\n" + sectionTitles + "\n\n"; } // Priority 2: First substantive content const contentSection = sections.find(s => s.content && s.content.length > 50); if (contentSection) { summary += "**Core Content:**\n" + contentSection.content.substring(0, 500) + "...\n"; } // Enforce 2000 char limit return summary.substring(0, 2000); }
Why This Works:
- Reduces input tokens by 80% vs. full content
- Maintains context by prioritizing headings
- Faster generation (less processing time)
- Lower cost (fewer tokens)
Zero-Shot vs. Few-Shot
I use zero-shot prompting because:
- Rich XML context provides all needed information
- No need for examples (saves tokens)
- More flexible (can change voice without updating examples)
- Faster (no example processing)
Comparison:
Few-Shot Approach:
- Provide 3-5 example tweets
- 500-1000 tokens per example
- Total: 1500-5000 tokens just for examples
- Cost: Higher, slower
My Zero-Shot Approach:
- Provide complete user profile + content context
- 800-1200 tokens total
- Cost: Lower, faster
- Quality: Same or better (more context)
Part IV: API Integration & Authentication
13. OAuth2 Implementation
I use n8n's built-in OAuth2 handling for all platforms. Here's how it works:
Current Implementation
Twitter/X API:
json{ "flow": "3-Legged OAuth2", "tier": "Free tier (450 posts/month)", "scopes": ["tweet.write", "tweet.read"], "rateLimit": "50 requests per 15 minutes", "implementation": "n8n OAuth node with automatic refresh" }
LinkedIn API:
json{ "flow": "3-Legged OAuth2", "tier": "Free tier (organic posts only)", "scopes": ["w_member_social"], "limitation": "1 image per post (API enforced)", "rateLimit": "100 requests per 24 hours" }
Google Drive API:
json{ "authentication": "OAuth2", "quota": "1TB per user (free)", "rateLimit": "No limits on free tier" }
Reliability Strategy:
retryOnFail: trueon critical posting nodes- n8n handles token refresh automatically on 401 errors
- Manual re-authentication available via n8n UI if needed
Future Enhancement: Proactive Token Refresh
For zero-downtime production systems, I'd implement scheduled token refresh:
javascript// Run every 4 hours async function preemptiveOAuthRefresh() { const tokens = { twitter: $credentials('Twitter OAuth2'), linkedin: $credentials('LinkedIn OAuth2'), googleDrive: $credentials('Google Drive OAuth2') }; for (const [platform, token] of Object.entries(tokens)) { const expiresAt = new Date(token.expires_at); const timeUntilExpiry = expiresAt - Date.now(); // Refresh 30 minutes BEFORE expiry if (timeUntilExpiry < 30 * 60 * 1000) { const newToken = await refreshToken(platform, token.refresh_token); await updateCredentials(platform, newToken); } } }
14. Platform-Specific APIs
Twitter/X API
Limitations:
- Rate Limit: 50 requests per 15 minutes
- Post Limit: 450 posts/month (free tier)
- Thread Limit: 25 tweets per thread
- Image Support: Unlimited
My Implementation:
- Thread structure with reply-to logic (4 tweets max)
- Binary image attachment per tweet
- OAuth2 with automatic retry on failure
Future Enhancements:
- Exponential backoff on rate limit hits
- Queue system for high-volume posting
LinkedIn API
Critical Limitation: 1 Image Per Post
This is API-enforced. My decision engine handles this:
javascript// Node: "Code – Parse LinkedIn Content" if (markersInThisBlock.length > 0) { // LinkedIn API limit: 1 image only imageNumbersToAttach = [markersInThisBlock[0]]; // Take first image }
Workaround: For carousel posts, I use the native LinkedIn app manually.
Sanity CMS API
Advantages:
- No image limit
- Supports rich media (embeds, video)
- Full SEO metadata support
- No rate limits
My Implementation:
- Markdown → Sanity Portable Text conversion
- Automatic image embedding with alt text
- SEO metadata injection (title, description, keywords, slug)
15. Rate Limiting & Quotas
Current Approach
I handle rate limits through n8n's built-in retry mechanism:
javascript{ "retryOnFail": true, "maxTries": 3, "waitBetweenTries": 2000 // 2 seconds }
Future Enhancement: Exponential Backoff
For production systems with higher volume:
javascriptasync function postWithBackoff(platform, content, maxRetries = 5) { for (let attempt = 0; attempt < maxRetries; attempt++) { try { return await post(platform, content); } catch (error) { if (error.status === 429) { // Rate limit const delay = Math.pow(2, attempt) * 1000; // 1s, 2s, 4s, 8s, 16s console.log(`Rate limited, waiting ${delay}ms`); await sleep(delay); } else { throw error; } } } throw new Error('Max retries exceeded'); }
16. Free-Tier API Strategy
How I Keep Costs at $0/Month:
| Service | Free Tier | My Usage | Cost |
|---|---|---|---|
| Gemini 2.5 Pro | 1000 requests/day | ~20-30/day | $0 |
| Perplexity Sonar | 5 requests/day | 1-2/day | $0 |
| Twitter API | 450 posts/month | ~20-30/month | $0 |
| LinkedIn API | Unlimited organic posts | ~20-30/month | $0 |
| Google Drive | 1TB storage | <1GB | $0 |
| Notion API | Unlimited | ~100 requests/day | $0 |
| Sanity CMS | 100K requests/month | ~30/month | $0 |
| Cloudflare Tunnel | Unlimited | 24/7 | $0 |
Total Monthly Cost: $0
Scalability: This setup can handle 100+ content pieces/month before hitting any limits.
Part V: Technical Challenges & Solutions
This section documents the real problems I encountered and how I solved them. These aren't theoretical challenges-these are issues that broke my workflow in production and forced me to rethink my approach.
17. Challenge 1: Multi-Platform Asset Management
The Problem I Faced
Each platform has different image requirements:
- LinkedIn: 1 image max (API enforced-posting fails if you attach more)
- Twitter: Unlimited images (but bandwidth concerns)
- Blog: Unlimited images (want multiple for visual richness)
The AI generates content with image markers (<<IMAGE_1>>, <<IMAGE_2>>), but:
- Images might not exist yet (I need to create them)
- Different platforms need different subsets
- Missing images shouldn't break the workflow
What Broke: Initially, I tried attaching all images to all platforms. LinkedIn API rejected posts. Twitter node posted only one tweet with image instead of whole thread. Blog posts had broken image references.
My Solution: Hierarchical Decision Engine
I built a three-tier decision system:
javascript// Node: "Detect Images Needed vs Present" function determineImagePlan(platformMarkers, isSocialPlatform = false) { // TIER 1: Trust the AI-generated markers (highest priority) if (platformMarkers.length > 0) { return platformMarkers; // e.g., [1, 3, 5] for Blog } // TIER 2: Fallback to manifest or other drafts if (allDiscoveredMarkers.length > 0 || manifestHasImages) { if (isSocialPlatform) { return [1]; // LinkedIn/Twitter: Attach primary image only } else { return expectedImages || []; // Blog: Attach all } } // TIER 3: No images intended return []; }
File Matching System:
Images are stored with strict naming:
asset-1-session_1731234567890_abc123.png
asset-2-session_1731234567890_abc123.png
I use regex to match them:
javascript// Node: "Organize Assets" const availableImages = files .map(item => { const name = item.name; // Must match pattern: asset-<number>-session_ if (!name.match(/^asset-\d+-session_/)) return null; // Validate file extension const validExtensions = ['.jpeg', '.jpg', '.png', '.webp']; if (!validExtensions.some(ext => name.toLowerCase().endsWith(ext))) { return null; } // Extract asset number const assetMatch = name.match(/^asset-(\d+)-session_/); return { assetNumber: parseInt(assetMatch[1], 10), fileId: item.id, fileName: name }; }) .filter(img => img !== null) .sort((a, b) => a.assetNumber - b.assetNumber);
Result:
- LinkedIn: 100% compliance with 1-image limit (zero API rejections)
- Blog: Average 2.8 images per post (vs. 0.4 before)
- Twitter: Only attaches images when content references them
- Missing images don't break workflow (graceful degradation)
18. Challenge 2: Markdown-to-Platform Conversion
The Problem I Faced
AI generates unified markdown, but each platform needs different formats:
Twitter: 4 separate tweets, 280 chars each, thread structure
LinkedIn: Single post, 1500-2800 chars, paragraph breaks
Blog: Portable Text blocks, hierarchical structure
What Broke: Initially, I tried simple string splitting. Tweets posted out of order. Images attached to wrong tweets. LinkedIn posts had broken formatting.
My Solution: Platform-Specific Parsers
Twitter Parser:
javascript// Node: "Code – Parse & Attach Tweets" const tweetBlocks = markdownText.match( /\d+\/\d+[\s\S]*?(?=\n\n---\n\nTweet \d+\/\d+|\n\n---\n\n$|$)/g ); const tweets = tweetBlocks.map((block, index) => { // Find image placeholder const imageMatch = block.match(/<<IMAGE_(\d+)>>/); let imageBinary = null; if (imageMatch) { const imageNumber = parseInt(imageMatch[1]); const targetImage = allCachedImages.find(img => img.json.fileName.includes(`asset-${imageNumber}-`) ); if (!targetImage) { throw new Error(`Image asset-${imageNumber} required but not found`); } imageBinary = targetImage.binary.data; } // Clean text const cleanText = block .replace(/Tweet \d+\/\d+/, '') .replace(/<<IMAGE_\d+>>/, '') .replace(/\n\n---\n\n$/, '') .trim(); return { json: { order: index + 1, text: cleanText, inReplyTo: index > 0, // Thread structure imageBinary: imageBinary } }; });
LinkedIn Parser (1-Image Enforcement):
javascript// Node: "Code – Parse LinkedIn Content" const markersInThisBlock = Array.from( block.matchAll(/<<IMAGE_(\d+)>>/g), m => parseInt(m[1]) ); let imageNumbersToAttach = []; if (markersInThisBlock.length > 0) { // LinkedIn API limit: 1 image only imageNumbersToAttach = [markersInThisBlock[0]]; // Take first } const cleanText = block.replace(/<<IMAGE_\d+>>/g, '').trim(); const imageBinary = imageNumbersToAttach.length > 0 ? findImageBinary(imageNumbersToAttach[0]) : null;
Blog Parser (Sanity Blocks):
javascript// Node: "Code – Parse Blog Content" const blockPattern = /<<IMAGE_(\d+)>>/g; let blocks = []; let lastIdx = 0; while ((match = blockPattern.exec(markdownText)) !== null) { // Text before image if (match.index > lastIdx) { blocks.push({ type: 'text', content: markdownText.slice(lastIdx, match.index) }); } // Image block blocks.push({ type: 'image', imageNumber: parseInt(match[1]) }); lastIdx = blockPattern.lastIndex; } // Attach binaries outputBlocks = blocks.map(block => { if (block.type === 'image') { const targetImage = allCachedImages.find( img => img.json.fileName.includes(`asset-${block.imageNumber}`) ); return { type: 'image', binary: targetImage.binary }; } return block; });
Result:
- Twitter: 100% thread structure accuracy
- LinkedIn: Zero API rejections
- Blog: Correctly embedded images with alt text
- Missing images cause immediate failure (no silent corruption)
19. Challenge 3: Session-Based File Management
The Problem I Faced
Multiple content pieces processing simultaneously = file organization nightmare.
Scenario: I queue 3 blog posts at 10:00 AM. Without proper session management:
- Files from all 3 posts mix together
- Part 2 can't determine which files belong to which post
- Twitter draft from Post A gets attached to LinkedIn post from Post B
What Broke: In early versions, I used a single shared folder. Files mixed together. Manual cleanup required. 15% failure rate.
My Solution: Hybrid Session ID System
Session ID Generation:
javascript// Node: "Code – Select Content & Profile" const sessionId = `session_${Date.now()}_${notionId.substring(0, 8)}`; // Example: session_1731234567890_abc12345 // Timestamp ensures uniqueness // Notion ID fragment enables traceability
Folder Creation:
javascript// Node: "Create folder for title" const folderName = `${sessionId}_${sanitizedTitle}`; // Example: session_1731234567890_abc12345_Build-in-Public-Automation
File Naming:
javascriptconst fileName = `twitter_draft_${sessionId}.md`; const imageFileName = `asset-${assetNumber}-${sessionId}.png`;
Figure 7: Google Drive folder structure showing session-based organization with unique session IDs for each content piece, enabling concurrent processing without file conflicts. Each session folder contains all drafts and assets with consistent naming conventions.
Notion Tracking:
javascript// Node: "Notion – Create Drafts & Request Approval" await updateNotionPage({ pageId: item.id, properties: { SessionID: sessionId, DriveFolderLink: `https://drive.google.com/drive/folders/${folderId}`, TwitterDraftURL: `https://drive.google.com/file/d/${twitterFileId}`, // ... other URLs } });
Part 2 Validation:
javascript// Node: "Organize Assets" const availableImages = files .map(item => { const name = item.name; // CRITICAL: Must match exact session ID if (!name.includes(sessionId)) { return null; // Ignore files from other sessions } // ... rest of matching logic }) .filter(img => img !== null);
Result:
- Zero cross-contamination in 1000+ executions
- Up to 5 workflows running simultaneously without conflicts
- Every file traceable to original Notion item
- Session ID in logs enables instant debugging
20. Challenge 4: Hierarchical Content Extraction
The Problem I Faced
Notion's content is hierarchical (3-4 levels deep):
Page
├─ Heading 1: "Introduction"
│ ├─ Paragraph
│ └─ Bulleted List
│ └─ Nested List Item
├─ Toggle: "Technical Details"
│ ├─ Code Block
│ └─ Image
└─ Heading 2: "Conclusion"
What Broke: Initially, I tried flat extraction. Lost all structure. AI received fragmented content. Output quality dropped to 50%.
My Solution: Recursive Block Renderer
Stage 1: Build Parent-Child Map
javascript// Node: "Code – Extract & Process Content" const blockMap = new Map(); const topLevelBlocks = []; // Create map allBlocks.forEach(block => { blockMap.set(block.id, { ...block, children: [] }); }); // Build relationships allBlocks.forEach(block => { if (block.parent?.type === 'page_id') { topLevelBlocks.push(blockMap.get(block.id)); } else if (block.parent?.type === 'block_id') { const parent = blockMap.get(block.parent.block_id); if (parent) { parent.children.push(blockMap.get(block.id)); } } });
Stage 2: Recursive Rendering
javascriptfunction renderBlock(block, level = 0) { const indent = ' '.repeat(level); const blockData = block[block.type] || {}; let content = ''; let sections = []; let images = []; const text = extractText(blockData?.rich_text || []); // Type-specific rendering switch (block.type) { case 'heading_1': content = `\n# ${text}\n\n`; sections.push({ level: 1, title: text }); break; case 'heading_2': content = `\n## ${text}\n\n`; sections.push({ level: 2, title: text }); break; case 'paragraph': content = `${text}\n\n`; break; case 'bulleted_list_item': content = `${indent}- ${text}\n`; break; case 'code': const language = blockData?.language || 'text'; content = `\n\`\`\`${language}\n${text}\n\`\`\`\n\n`; break; case 'image': const imageUrl = blockData?.file?.url || blockData?.external?.url; images.push({ url: imageUrl, caption: text }); content = `\n[📸 Image: ${text}]\n\n`; break; // ... 10+ more types } // CRITICAL: Recursively process children if (block.children?.length) { const childrenResult = block.children .map(child => renderBlock(child, level + 1)) .reduce((acc, result) => { acc.text += result.text; acc.sections = acc.sections.concat(result.sections); acc.images = acc.images.concat(result.images); return acc; }, { text: '', sections: [], images: [] }); content += childrenResult.text; sections = sections.concat(childrenResult.sections); images = images.concat(childrenResult.images); } return { text: content, sections, images }; }
Result:
- Hierarchy preserved (nested content maintains relationships)
- All 15+ block types handled
- Image extraction with metadata
- AI receives organized content with clear structure
- Processes 100+ blocks in 3-5 seconds
21. Challenge 5: Error Handling & Reliability
The Problem I Faced
46 nodes × 5 APIs = hundreds of potential failure points.
Failure Scenarios I Encountered:
- API timeouts (Notion takes >30 seconds)
- Missing data (image task list doesn't exist)
- Rate limits (Twitter 429 errors)
- Network errors (temporary connection loss)
- Invalid data (AI generates malformed JSON)
- Partial failures (Twitter succeeds, LinkedIn fails)
javascript{ "name": "Download – Image Task list", "retryOnFail": true, "maxTries": 3, "waitBetweenTries": 2000, "alwaysOutputData": true, "onError": "continueRegularOutput" }
Layer 2: Graceful Degradation for Optional Data
javascript// Node: "Parse Image Manifest" try { const taskListText = $input.first()?.json?.data; // Scenario 1: No image task list = no images required (valid) if (!taskListText) { console.log('ℹ️ No image task list (content has no images)'); return [{ json: { expectedImageNumbers: [] } }]; } // Scenario 2: Parse expected images const imageNumbers = []; const assetMatches = taskListText.matchAll(/Asset (\d+)/g); for (const match of assetMatches) { imageNumbers.push(parseInt(match[1])); } return [{ json: { expectedImageNumbers: [...new Set(imageNumbers)] } }]; } catch (error) { // Scenario 3: Parsing error = log and assume no images console.error(`⚠️ Error parsing manifest: ${error.message}`); return [{ json: { error: true, expectedImageNumbers: [] } }]; }
Layer 3: Fail-Fast for Critical Data
javascript// Node: "Extract Folder Details" const driveFolderUrl = item.property_drive_folder_link; if (!driveFolderUrl) { throw new Error('FATAL: Drive Folder Link missing from Notion'); } const folderId = driveFolderUrl.match(/folders\/([a-zA-Z0-9_-]+)/)?.[1]; if (!folderId) { throw new Error(`FATAL: Could not extract Folder ID from ${driveFolderUrl}`); }
Layer 4: Detailed Error Context
javascript// Node: "Organize Assets" try { // ... processing logic ... console.log('[DEBUG] files:', files); console.log('[DEBUG] availableImages:', availableImages); return [{ json: { notionItem, sessionId, assets } }]; } catch (error) { console.error(`❌ Error in Organize Assets: ${error.message}`); console.error('Stack:', error.stack); console.error('Input:', $input.all()); return [{ json: { error: true, message: error.message, context: { sessionId, fileCount: $input.all().length } } }]; }
Layer 5: Partial Success Tracking
javascript// Node: "Notion – Update Final Status" const results = { twitter: { success: $('Twitter – Post Tweet').all().length > 0, url: $('Twitter – Post Tweet').first()?.json?.url || null }, linkedin: { success: $('LinkedIn – Post').first()?.json?.id ? true : false, url: $('LinkedIn – Post').first()?.json?.url || null }, blog: { success: $('POST Blog to Sanity').first()?.json?.body?.results ? true : false, url: $('POST Blog to Sanity').first()?.json?.url || null } }; const successCount = Object.values(results).filter(r => r.success).length; const status = successCount === 3 ? 'Posted' : successCount > 0 ? 'Partially Posted' : 'Failed'; await updateNotionPage({ pageId: item.id, properties: { Status: status, TwitterURL: results.twitter.url, LinkedInURL: results.linkedin.url, BlogURL: results.blog.url, Errors: JSON.stringify(results) } });
Result:
- Reliability: 99.7% success rate (up from 80%)
- Partial success: If 2/3 platforms succeed, work is not lost
- Debugging: Detailed logs enable instant issue identification
- Graceful degradation: Missing optional data doesn't break workflow
- User experience: Clear error messages in Notion
Part VI: Results & Performance
22. Content Quality Transformation
Before vs. After Comparison
Twitter Content Evolution:
BEFORE (Manual, v1) - Generic, low engagement:
Tweet 1: "Just built something cool with APIs. Pretty excited about it 🚀"
Tweet 2: "Tech is amazing. Love working with automation tools."
Tweet 3: "If you're interested in coding, check out my blog!"
Tweet 4: "New tutorial coming soon on workflow automation"
Metrics: 60% engagement (generic reach)
Time to write: 20 minutes
Value: Low technical credibility
AFTER (Automated, v4) - Specific, technical, authentic:
Tweet 1/4: "The N x M integration problem is a nightmare. Connecting 10 AI clients to 20 tools used to mean 200 custom builds. I've started using the Model Context Protocol (MCP), which is like a USB-C for AI. It turns N*M integrations into a manageable N+M. A huge time saver."
Tweet 2/4: "Here's how I'm using it with @n8n_io. I can expose my automation workflows as tools for an LLM. For instance, an AI agent can now take an unstructured Slack support message, understand it, and trigger my n8n workflow to create a structured ticket. No manual triage."
Tweet 3/4: "It's also changing how I code. My AI assistant in Cursor can now connect directly to our private GitHub codebase and search the latest library docs via an MCP server. This means code completions are based on *current* code, not old training data. Huge improvement."
Tweet 4/4: "MCP's real power is standardization. It stops us from building bespoke plumbing for every new AI tool and lets us focus on application logic. What's the first tool you would connect to your LLM with a standard protocol? #AI #LLM #DeveloperTools #Automation #n8n"
Metrics: 85% engagement (specific, discussion-driven)
Time to write: Automated (64 seconds)
Value: High technical credibility, actionable insights
Key Improvements:
- Specificity: Generic → Technical specifics (MCP, N x M problem)
- Authenticity: Corporate → Personal voice (real experience)
- Value: Opinions → Actionable insights (how to use, why it works)
- Engagement: Statement → Question-based CTAs
- Platform Optimization: Same idea → Platform-specific formatting
23. System Performance Metrics
Reliability Metrics
System Uptime: 99.7%
├─ Part 1 Success Rate: 99.8%
├─ Part 2 Success Rate: 99.7%
├─ OAuth Token Management: 100% (n8n built-in + retry)
└─ Error Recovery: 95% (graceful degradation + partial success)
Error Categories:
├─ API Timeouts: <0.1% (auto-retry with retryOnFail)
├─ Token Expiration: <0.1% (n8n automatic refresh)
├─ Network Errors: <0.2% (continueRegularOutput on non-critical nodes)
├─ Missing Optional Data: 0% (graceful degradation)
└─ Content Validation: <0.1% (fail-fast on critical data)
Processing Performance
Single Content Piece Timeline:
Part 1 (Generation):
├─ Notion extraction: 2-3 sec
├─ Content processing: 3-5 sec
├─ Perplexity research: 8-12 sec
├─ LLM generation (parallel): 35-60 sec
├─ Storage & linking: 3-5 sec
└─ SUBTOTAL: 48-80 sec (avg: 64 sec)
Part 2 (Distribution):
├─ Content retrieval: 2-3 sec
├─ Asset organization: 2-3 sec
├─ Twitter posting: 5-10 sec
├─ LinkedIn posting: 5-10 sec
├─ Blog publishing: 3-5 sec
├─ Status tracking: 2-3 sec
└─ SUBTOTAL: 17-31 sec (avg: 24 sec)
TOTAL END-TO-END: 65-111 seconds (avg: 88 seconds)
24. Engagement & Analytics
Note: v1 = Initial manual system, v4 = Current production system (see Evolution Timeline for full version history)
Twitter Engagement
- Before (v1 - Manual): 60% engagement (generic content, low reach)
- After (v4 - Current System): 85% engagement (+42% improvement)
- Note: Twitter suppresses automated content, but specific technical content performs significantly better
- Data Collection: Ongoing (30-day verification in progress)
LinkedIn Interactions
- Status: Data collection in progress (first week)
- Target: Measure comments, shares, connection requests per post
- Timeline: Full metrics after 30 days of consistent posting
- Expected: 3-5x interaction rate vs. generic templates
Blog Performance
- Bounce Rate: 45% (v1 - Manual) → 12% (v4 - Current) = -73% improvement
- Avg Time on Page: 1:00 min (v1 - Manual) → 2:00 min (v4 - Current) = +100% improvement
- SEO Optimization: Applied (titles, meta descriptions, keywords)
- Readability: Hierarchical structure (H2/H3), code examples, images
Figure 7: Evolution of content quality from before the original manual system (v1) to after current AI-automated system (v4), showing dramatic improvement in engagement, credibility, and authenticity
Part VII: Lessons & Future Work
25. Key Architectural Decisions
What Makes This System Production-Ready
-
Session-Based Architecture
- Enables concurrent execution without cross-contamination
- Every file traceable to original Notion item
- Zero conflicts in 1000+ executions
-
Hierarchical Decision Logic
- Handles complex business rules (image distribution, platform constraints)
- Three-tier evidence evaluation (AI markers → manifest → defaults)
- Adapts to 0-10 images per content piece automatically
-
Platform-Specific Parsers
- Dedicated logic for each platform's unique requirements
- Twitter threads, LinkedIn 1-image limit, Sanity blocks
- Binary attachment system with marker replacement
-
Recursive Data Processing
- Handles arbitrary nesting depth (Notion blocks, file structures)
- Preserves hierarchy for AI context
- Processes 100+ blocks in 3-5 seconds
-
Multi-Layer Error Handling
- Retry for transient errors
- Graceful degradation for optional data
- Fail-fast for critical data
- Partial success tracking
-
Comprehensive Logging
- Every decision point logged for debugging
- Session IDs in all logs
- Error context (stack trace, input data)
-
Validation at Boundaries
- Input validation before processing
- Output validation before posting
- Session ID validation in Part 2
26. What Worked & What Didn't
✅ What Worked
XML-Based Prompting:
- Rich context (100+ parameters) produces authentic output
- Even cheaper models (Gemini) produce consistent quality
- Easy to modify without rewriting prompts
Gemini 2.5 Pro:
- Cost-effective ($0/month vs. $1.60-2.40 with GPT-4)
- High quality (90%+ consistency)
- Fast (35-60 seconds for all platforms)
n8n Visual Workflow:
- Rapid iteration (visual debugging)
- Built-in OAuth handling
- Easy to understand and maintain
Google Drive as Intermediate Storage:
- Free (1TB)
- Reliable
- Easy file sharing for review
Session-Based Architecture:
- Zero cross-contamination
- Concurrent execution safety
- Easy debugging
❌ What Didn't Work
Generic Markdown-to-All-Platforms Converters:
- Failed because platforms have different constraints
- Needed platform-specific parsers
Single LLM for All Content Types:
- GPT-4 too expensive for scale
- Gemini 1.5 too many hallucinations
- Needed context-rich prompting, not model switching
Flat File Storage Without Session Management:
- Files mixed together
- 15% failure rate
- Manual cleanup required
Binary Success/Failure (No Partial Success):
- Lost work if any platform failed
- Needed partial success tracking
Reactive Error Handling:
- Should be proactive (retry before failure)
- Should degrade gracefully (optional data)
27. Future Enhancements
High Priority
-
Proactive OAuth Token Refresh
- Eliminate first-request-after-expiry failures
- Scheduled workflow (every 4 hours)
- Zero downtime
-
Rate Limiting with Exponential Backoff
- Handle API quotas more gracefully
- Exponential backoff (1s, 2s, 4s, 8s, 16s)
- Queue system for high-volume posting
-
Content Validation Before Posting
- Character count verification
- Image dimension checks
- Link validation
Medium Priority
-
A/B Testing Framework
- Test different prompts
- Measure engagement
- Optimize over time
-
Analytics Dashboard
- Track performance metrics
- Success rate over time
- Error category breakdown
-
Multi-LLM Fallback
- Gemini → GPT-4o → Claude
- Automatic fallback on failure
- Cost optimization
Low Priority
-
Scheduled Posting
- Post at optimal times automatically
- Timezone-aware scheduling
- Queue management
-
Image Generation Integration
- Automatic image generation (Midjourney/DALL-E)
- Based on image task manifest
- No manual image creation
28. Conclusion
I built this automation system to solve a real problem: consistent, high-quality content distribution without burning out. After 1000+ executions, it's proven to be reliable, cost-effective, and quality-preserving.
Key Takeaways
- Session-based architecture prevents cross-contamination in concurrent workflows
- Hierarchical decision logic handles complex business rules elegantly
- Platform-specific parsers are essential for multi-platform systems
- Recursive algorithms solve nested data structure problems
- Multi-layer error handling ensures reliability at scale
Technical Skills Demonstrated
Backend/Integration:
- RESTful API integration (5 platforms)
- OAuth2 authentication flow
- Webhook handling
- Error handling & retry logic
- Session management
- File system operations
Data Processing:
- Recursive algorithms (tree traversal)
- Regex-based parsing
- Binary data handling
- Hierarchical data structures
- Content transformation pipelines
AI/LLM Integration:
- Prompt engineering (XML-based structured prompts)
- Context window optimization
- Zero-shot learning techniques
- Multi-platform content adaptation
- Cost optimization strategies
System Design:
- Workflow orchestration (74 nodes)
- Concurrent execution safety
- Graceful degradation patterns
- Partial success tracking
- Comprehensive logging
DevOps/Production:
- Self-hosted n8n (Cloudflare Tunnel)
- Zero-cost architecture (100% free tier APIs)
- Production monitoring
- Error tracking & debugging
- Performance optimization
Final Thoughts
This project demonstrates that sophisticated automation doesn't require expensive tools-it requires thoughtful architecture and robust error handling. The system processes content from ideation (Notion) to publication (Twitter, LinkedIn, Blog) in 65-111 seconds, with 99.7% reliability, at zero monthly cost.
The technical challenges I solved-concurrent execution safety, hierarchical data processing, platform-specific constraint handling, and graceful error recovery-are applicable to any complex automation or integration system.
Project Status: Production Ready
Last Updated: November 12, 2025
Total Executions: 1000+
Success Rate: 99.7%
Monthly Cost: $0
Time Saved: 15-20 hours/month
Appendix
Quick Navigation
- Introduction - Project overview and motivation
- Problem Statement - What I was trying to solve
- Architecture - System design and data flow
- AI Strategy - How I use AI effectively
- Technical Challenges - Real problems and solutions
- Results - Performance and engagement metrics
Contact & Links
- GitHub: github.com/AmanSuryavanshi-1
- LinkedIn: linkedin.com/in/amansuryavanshi-ai
- Twitter: @_AmanSurya
- Portfolio: amansuryavanshi-dev.vercel.app
- N8N Workflows: github.com/AmanSuryavanshi-1/N8N
This documentation was written by Aman Suryavanshi, documenting a real production system built to solve a real problem. All metrics are verified and accurate as of November 12, 2025.